Serverless es un concepto nacido en la Nube. Su gran éxito es ser una arquitectura para backend, del lado del servidor (Server-side), que no tiene estado, de ejecución rápida y que responde a eventos. Literalmente, se traduce como “sin servidor”. Y aquí es donde empieza el conflicto.

Y es que serverless es de las tecnologías con nombre más traicionero que existen. Se traduce como “sin servidor”. Pero en realidad se refiere a un tipo de arquitectura en la que el servidor no es importante para el desarrollador. Se ejecutan en entornos aislados, como en contenedores específicos. Pero evidentemente, estos entornos y/o contenedores, se ejecutan en uno o varios servidores.
La forma más conocida de programar serverless es usar las plataformas de “Function as a Service” (FaaS). Este tipo de servicios está totalmente gestionado por el proveedor cloud que utilicemos. Y se caracterizan por basarse en funciones como unidad de trabajo. Estas funciones:
- Serán independientes, pequeñas y basadas en una unidad lógica.
- Podrán recibir y devolver parámetros.
- No tendrán estado.
- Estarán diseñadas para ser rápidas y efímeras: con cada llamada, se instancia todo lo necesario, se ejecuta la función y libera todos los recursos de la memoria.
- Deberán ser escalables. Pudiendo tener tantas instancias como sean necesarias, ejecutándose en el mismo momento. Incluso en paralelo.
- Sus desencadenadores serán eventos: bien sea una petición HTTP, un evento en una base de datos, la respuesta a un mensaje en una cola…
Hoy en día tenemos muchísimas variantes de estos servicios, aunque los más importantes son los que han implementado las “Big Three” de la nube: Amazon, Google y Microsoft. Y como todos sabemos de qué pie cojeo, pues vamos a hablar de la implementación de Microsoft: Azure Functions.
Mi primera Function
La forma más fácil de programar para Azure Functions es usar un Visual Studio Enterprise o Community. Desde ahí crearemos un nuevo proyecto, seleccionaremos como tipo “Cloud”, y dentro de las diferentes propuestas de plantilla, la denominada como “Azure Functions”.
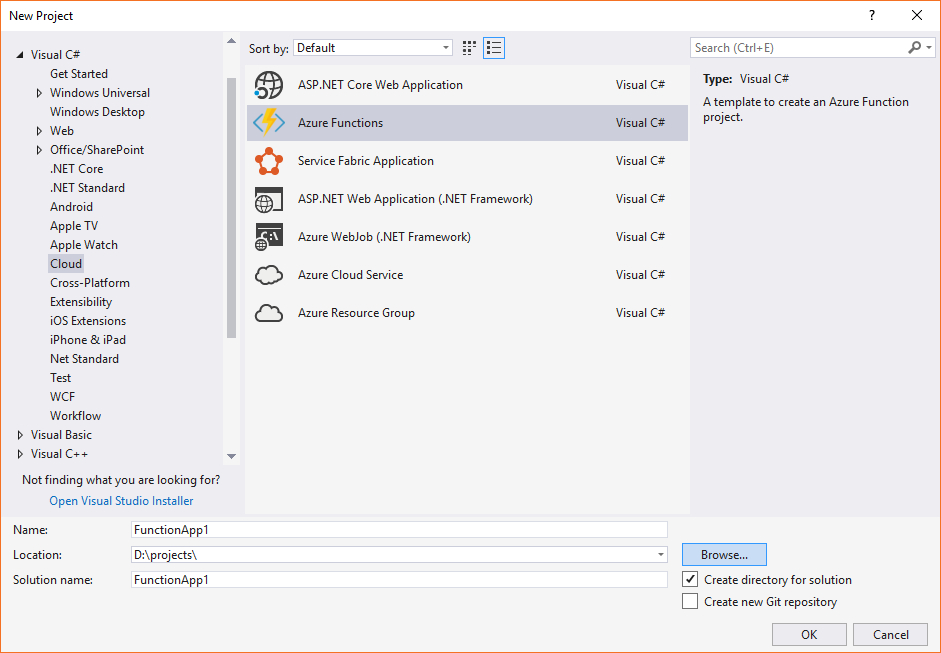
Entonces nos pedirá cierta configuración adicional para el proyecto. La primera será seleccionar el Framework, que en este caso nos hemos decantado por “Azure Functions v2 (.Net Core)”. Después, como vamos a implementar una API Rest, hemos escogido “Http trigger” como desencadenador por defecto. Y finalmente, en el nivel de acceso le hemos puesto “Anonymous”, para que sea pública y no haga falta autenticarse.
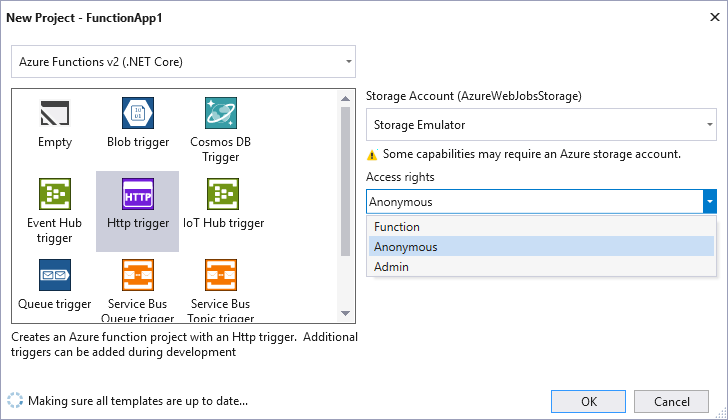
Si ahora ejecutamos el proyecto, nos aparecerá una consola donde se indica una URL donde se ha montado nuestra Function en la máquina local. Para lanzarla, abriremos el navegador e introduciremos esa URL con el parámetro “name” y un valor. En mi caso ha sido: “http://localhost:7071/api/Function1?name=MaxPower”.
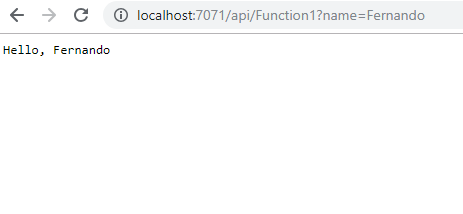
Está muy bien tener resultados con solo 30’’ de clics en la pantalla :). Os prometo que no os robaré mucho más tiempo implementando una API Rest.
Azure Function API
Si queremos una API, es posible que necesitemos previamente un tipo de recurso que utilizar en la misma. En este caso hemos decidido usar un “Todo”, para implementar una API de gestión de tareas:
public class Todo
{
public string Id { get; set; } = Guid.NewGuid().ToString("n");
public DateTime Created { get; set; } = DateTime.UtcNow;
public string Text { get; set; }
public bool Done { get; set; }
}
Para almacenar este tipo de datos nos hemos decantado por un Sql Server. Por cuestiones de facilidad, hemos añadido una referencia al paquete de Nuget de Dapper. De esta forma podremos usar sus características de mapping con las conexiones con el motor de base de datos.
Así que hacer una función que lea de nuestra base datos y devuelva esos datos en formato API Rest será un código tan simple como el siguiente:
public static class TodoApi
{
[FunctionName("Todo_Get")]
public static async Task<IActionResult> SelectAsync(
[HttpTrigger(AuthorizationLevel.Anonymous, "get", Route = "todos")]
HttpRequest req,
ILogger log)
{
var cnnString = "my_connection_string";
using (var connection = new SqlConnection(cnnString))
{
connection.Open();
var todos = await connection.QueryAsync<Todo>("select Id, Created, Text, Done from dbo.Todos");
// QueryAsync<T> is a Dapper function. It maps the result of the query in to a IEnumerable<T>
if (todos.Count() == 0) return new EmptyResult(); // status code 204 No Content
return new OkObjectResult(todos); // status code 200 Ok + body { ...todos }
}
}
}
Uno de los típicos retos que vamos a encontrar usando Microsoft Azure, es que nos da la posibilidad de usar settings de aplicación configurados en el propio entorno de Azure. De esta forma las aplicaciones no tienen por qué conocer los datos de conexión de, por ejemplo, una base de datos. Esa información se la proveerá el propio entorno.
En el caso de Azure Functions, existen los Application Settings, que pueden ir en archivos de configuración json o también en forma de variables de entorno. Para poder recoger estos valores de cualquiera de las dos fuentes, tendremos que instanciar un “ConfigurationBuilder” para así poder crear un “IConfigurationRoot” de donde leer la información. A este fin crearemos la siguiente función que devolverá una cadena de conexión llamada “DefaultConnection” por defecto:
private static string GetConnectionString(ILogger log, ExecutionContext context)
{
var config = new ConfigurationBuilder()
.SetBasePath(context.FunctionAppDirectory)
.AddJsonFile("local.settings.json", optional: true, reloadOnChange: true)
.AddEnvironmentVariables()
.Build();
return config.GetConnectionString("DefaultConnection");
}
Después en el archivo del proyecto “local.settings.json”, añadiremos una sección nueva con las cadenas de conexión que usamos de forma local:
"ConnectionStrings": {
"DefaultConnection": "my_connection_string"
}
Y finalmente modificaremos nuestro código para que la “Function” recupere el “ExecutionContext” (añadiéndolo como parámetro) y para que la cadena de conexión la resuelva usando el código que hemos visto:
public static class TodoApi
{
[FunctionName("Todo_Get")]
public static async Task<IActionResult> SelectAsync(
[HttpTrigger(AuthorizationLevel.Anonymous, "get", Route = "todos")]
HttpRequest req,
ILogger log,
ExecutionContext context /*Added ExecutionContext parameter*/)
{
var cnnString = GetConnectionString(log, context); // call GetConnectionString(..) method
using (var connection = new SqlConnection(cnnString))
{
connection.Open();
var todos = await connection.QueryAsync<Todo>("select Id, Created, Text, Done from dbo.Todos");
if (todos.Count() == 0) return new EmptyResult();
return new OkObjectResult(todos);
}
}
}
Por último, y con el fin de conseguir tener una API completa, tendremos que ser capaces de leer información de la petición HTTP. Hay dos vías:
Url.Path parameter
Para leer un parámetro que nos encontramos en la propia URL de la API, lo primero que tendremos que hacer es añadirlo a la ruta de la función. Esto se especifica en el atributo “HttpTrigger”, en la variable “Route”. De la misma forma que haríamos con Asp.Net, indicando el nombre de la variable entre llaves:
[HttpTrigger(AuthorizationLevel.Anonymous, "get", Route = "todos/{id}")]
HttpRequest req
Y para recogerlo, simplemente añadimos el parámetro a la función:
[FunctionName("Todo_GetById")]
public static async Task<IActionResult> SelectByIdAsync(
[HttpTrigger(AuthorizationLevel.Anonymous, "get", Route = "todos/{id}")] /* the 'id' parameter in the Route*/
HttpRequest req,
ILogger log,
ExecutionContext context,
string id /*the 'id' parameter as a function parameter*/)
{
// ...
}
Request.Body
Por otro lado, si queremos recoger el valor del cuerpo de la petición HTTP, tendremos que usar un deserializador de json. En nuestro proyecto ya tendremos incluido el NewtonSoft.Json. Así que deberíamos serializarlo leyéndolo de la Request:
[FunctionName("Todo_Create")]
public static async Task<IActionResult> CreateAsync(
[HttpTrigger(AuthorizationLevel.Anonymous, "post", Route = "todos")]
HttpRequest req,
ILogger log,
ExecutionContext context)
{
var requestBody = await new StreamReader(req.Body).ReadToEndAsync();
var input = JsonConvert.DeserializeObject<Todo>(requestBody);
// ...
}
API Rest
Conociendo estos detalles, ya no tendremos problemas en implementar una versión completa de una API Rest basada en Azure Functions y con una base de datos hospedada en un Azure Sql Database. La podéis ver a continuación:
public static class TodoApi
{
[FunctionName("Todo_Get")]
public static async Task<IActionResult> SelectAsync(
[HttpTrigger(AuthorizationLevel.Anonymous, "get", Route = "todos")]
HttpRequest req,
ILogger log,
ExecutionContext context)
{
var cnnString = GetConnectionString(log, context);
using (var connection = new SqlConnection(cnnString))
{
connection.Open();
var todos = await connection.QueryAsync<Todo>("select Id, Created, Text, Done from dbo.Todos");
if (todos.Count() == 0) return new EmptyResult();
return new OkObjectResult(todos);
}
}
[FunctionName("Todo_GetById")]
public static async Task<IActionResult> SelectByIdAsync(
[HttpTrigger(AuthorizationLevel.Anonymous, "get", Route = "todos/{id}")]
HttpRequest req,
ILogger log,
ExecutionContext context,
string id)
{
var cnnString = GetConnectionString(log, context);
using (var connection = new SqlConnection(cnnString))
{
connection.Open();
var todos = await connection.QueryAsync<Todo>("select Id, Created, Text, Done from dbo.Todos where Id = @id", new { id });
if (todos.Count() == 0) return new NotFoundResult();
return new OkObjectResult(todos.First());
}
}
[FunctionName("Todo_Create")]
public static async Task<IActionResult> CreateAsync(
[HttpTrigger(AuthorizationLevel.Anonymous, "post", Route = "todos")]
HttpRequest req,
ILogger log,
ExecutionContext context)
{
var requestBody = await new StreamReader(req.Body).ReadToEndAsync();
var input = JsonConvert.DeserializeObject<Todo>(requestBody);
var cnnString = GetConnectionString(log, context);
using (var connection = new SqlConnection(cnnString))
{
connection.Open();
await connection.ExecuteAsync("insert into dbo.Todos (Id, Created, Text, Done) values (@Id, @Created, @Text, @Done)", input);
var location = $"{req.Scheme}://{req.Host}{req.Path}{req.QueryString}/{input.Id}";
return new CreatedResult(location, input);
}
}
[FunctionName("Todo_Update")]
public static async Task<IActionResult> UpdateAsync(
[HttpTrigger(AuthorizationLevel.Anonymous, "put", Route = "todos/{id}")]
HttpRequest req,
ILogger log,
ExecutionContext context,
string id)
{
var requestBody = await new StreamReader(req.Body).ReadToEndAsync();
var input = JsonConvert.DeserializeObject<Todo>(requestBody);
var cnnString = GetConnectionString(log, context);
using (var connection = new SqlConnection(cnnString))
{
connection.Open();
await connection.ExecuteAsync("update dbo.Todos set Text = @Text, Done = @Done where Id = @Id", input);
return new OkObjectResult(input);
}
}
[FunctionName("Todo_Delete")]
public static async Task<IActionResult> DeleteAsync(
[HttpTrigger(AuthorizationLevel.Anonymous, "delete", Route = "todos/{id}")]
HttpRequest req,
ILogger log,
ExecutionContext context,
string id)
{
var cnnString = GetConnectionString(log, context);
using (var connection = new SqlConnection(cnnString))
{
connection.Open();
await connection.ExecuteAsync("delete from dbo.Todos where Id = @id", new { id });
return new OkObjectResult(id);
}
}
private static string GetConnectionString(ILogger log, ExecutionContext context)
{
var config = new ConfigurationBuilder()
.SetBasePath(context.FunctionAppDirectory)
.AddJsonFile("local.settings.json", optional: true, reloadOnChange: true)
.AddEnvironmentVariables()
.Build();
return config.GetConnectionString("DefaultConnection");
}
}
Conclusiones
Decidir desarrollar una arquitectura basada en serverless va a proporcionarnos muchas ventajas:
- Un coste de infraestructura basado solamente en el tiempo de ejecución. Sin tener que administrar nada en absoluto.
- Servicios más pequeños y mejor divididos. Siendo más fácil responder al cambio. Necesitando menos experiencia en complejas arquitecturas.
- Facilidad de automatización y menor time-to-market.
- Herramientas de monitorización out-of-the-box.
Pero siempre tendremos que conocer ciertas limitaciones:
- Es una tecnología nueva, y por tanto inmadura. Sin best-practices claras.
- Al tener todo tan dividido se multiplica la posibilidad de crear bloqueos de recursos y se añade mayor dificultad a la hora de controlarlos.
- El equipo de desarrollo tiene que tener muy interiorizada la filosofía de serverless a la hora de desarrollar.
- No es una arquitectura válida para procesos con gran carga de CPU y/o una larga duración.
- La arquitectura no aporta la velocidad necesaria en aplicaciones de tiempo real.
Así que queda en los problemas y consideraciones de cada proyecto el aplicar este modelo o no.