La semana pasada, los días 17, 18 y 19, estuvimos en la: Barcelona Developers Conference. El primer día por la mañana tuve el placer de, además de escuchar grandes ponencias, dar una charla sobre TDD en entornos .net. Y de coletilla, para el mundo real. Esta última frase que hacía del título algo parecido a una película mala de antena 3 por la tarde, venía a raíz de que mucha gente habla de TDD, y casi nadie de cómo se aplica realmente en el desarrollo diario.
Durante poco más de una hora intenté que los asistentes entendieran el por qué de esta metodología, cómo nos beneficia y cómo aplicarla en el desarrollo diario.
Si no pudisteis asistir, os diré que TDD son las siglas de Test Driven Development o en castellano: desarrollo guiado por las pruebas. Y es una técnica de desarrollo (de eXtreme Programing) que se basa en dos pasos: primero escribir la pruebas y después refactorizar.

La programación extrema engloba una serie de metodologías de programación ágiles, basadas en que a lo largo de un desarrollo van a ocurrir cambios de especificaciones y en lugar de intentar prevenir esto con una gran cantidad de código, que en ocasiones sobra, se decide adaptarse a esos cambios en cualquier fase del ciclo de vida del proyecto.
Sobre refactorización, es una técnica de la ingeniería del software que reestructura el código fuente sin cambiar su funcionalidad. Es decir, cambiar nombres de variables y métodos; reordenar el código; dividir una función en varias, … Algo que se conoce comúnmente como limpiar el código.
Las pruebas se escriben generalmente como pruebas unitarias (o unit tests en inglés). Una prueba unitaria es una forma de probar que un determinado bloque de código fuente, funciona correctamente. Es decir, mediante un pequeño programa comprobamos que cada porción de código fuente escrita funciona correctamente por separado. Y aunque estas pruebas no nos garantizan el funcionamiento global de la aplicación, pueden ser completadas con otro tipo de tests como los de integración, que comprueban que los diferentes artefactos funcionan correctamente unos con otros.
Para que se considere una prueba unitaria válida esta debe ser:
-
Automatizable: que significa que se puede ejecutar sin intervención humana. (CI)
-
Rápida: una prueba de este tipo no debe tardar un gran espacio de tiempo, tiene que ser prácticamente instantáneo el resultado de su ejecución.
-
Repetible: es decir, que la podemos ejecutar tantas veces como queramos sin obtener resultados diferentes cada vez. (una prueba que solo se puede ejecutar una vez no es una buena prueba).
-
Independiente: La ejecución de una prueba no debe influir en el resto de pruebas.
-
Profesional: y decimos profesional porque una prueba ha de hacerse con el mismo esfuerzo y dedicación que se haría cualquier otra parte de código. Hay que mantenerla y refactorizarla si es necesario.
Y como en mucho proyectos se tiende a olvidar este punto, lo repetimos ;) : una prueba unitaria es parte del código de la aplicación.
La estructura de un test unitario es simple:
-
Arrange: Disponer lo necesario para la prueba
-
Act: Realizar el acto que dará un resultado. La prueba en si.
-
Assert: comprobar que el resultado de la prueba es correcto.
Triple A como los videojuegos buenos…
Pero vamos a volver al concepto inicial: desarrollo guiado por las pruebas.
Generalmente expresado como Red -> Green -> Refactor, expone un diagrama de actividad simplificado de esta técnica.

Quiere decir que primero vamos a hacer un test unitario, comprobaremos que falla (Red), se completa el código de la forma más simple solo para que este pase (Green), y una vez funciona se refactoriza el código para así limpiarlo de malos nombres, espacios de nombre confusos o de código repetitivo…
Pero hemos dicho que esta es la versión simple…
En la versión real nosotros nos encontraríamos dentro de un proyecto. Como estaremos usando metodologías ágiles (algo como scrum), tendremos un product backlog para el sprint actual. Dentro de este encontraremos las historias de usuario que nos hablan de un requerimiento del software que estamos desarrollando. Y este requerimiento lo dividiremos en una o varias especificaciones.
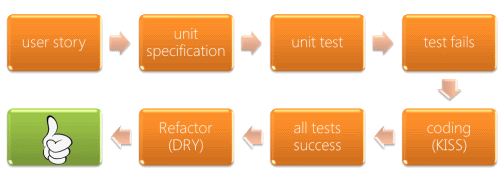
Una vez tenemos claro lo que tenemos que probar (la especificación) realizamos nuestro test unitario para acto seguido comprobar que este falla. Es muy importante comprobar esto, porque si no falla de buenas a primeras es porque nuestro test es posible que no compruebe nada en realidad.
Una vez tenemos nuestro test fallando podemos ponernos a codificar la mínima cantidad de código necesaria para que se vea cumplido. O seguir el principio KISS (Keep It Simple, Stupid!).
El siguiente paso sería comprobar que todas las pruebas que tenemos escritas pasan. Es decir, no solo la actual si no todas las demás porque podemos haber roto algo.
A partir de aquí se nos permitirá hacer una refactorización. Hay que ser pragmáticos y modificar el código, pero no su comportamiento. Y aplicar el principio DRY (Don’t Repeat Yourself). Entonces volvemos a comprobar de nuevo que todos los tests pasany pasamos a la siguiente especificación.
Me gustaría poneros un ejemplo (en la #bdc11 si lo hicimos, aunque muy rápido). Aunque creo que esto queda muy claro en vivo, leyendo es posible que no aclare demasiado… Así que explicaré cómo TDD nos llevó a crear clases y propiedades. Como tuvimos que desacoplar artefactos usando interfaces y al final nos decidimos a usar inyección de dependencias. Pero solo cuando el propio test nos llevó a ello.
Para terminar con este enorme post comentar los beneficios de esta técnica:
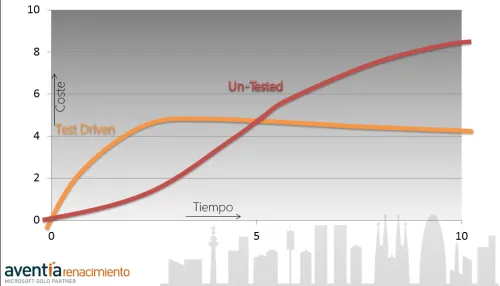
Esto que vemos es una curva de coste. Se suele utilizar para representar el coste de desarrollo de una aplicación en dependencia de la metodología utilizada. Muy común cuando la temática de la charla es sobre deuda técnica.
En el eje vertical vemos el coste y en el horizontal el tiempo. La línea naranja es el desarrollo usando test driven development y la roja el método “tradicional” de codificar.
La línea roja empieza a tener resultados muy rápidamente, pero el coste de desarrollo se va haciendo más grande con el tiempo. Al final existe una cantidad enorme de código sin ningún test que lo compruebe. Y el más mínimo cambio tiene un impacto en el coste muy grande.
Por otro lado vemos en un principio un desarrollo TDD es más costoso y tardará más tener resultados semejantes al otro. Eso sin contar con el tiempo de aprendizaje del equipo. Pero la curva se estabiliza rápidamente. Y una vez estabilizada y con una serie de test de respaldo, las modificaciones no se hacen a ciegas, y además son más simples, ya que esta técnica nos ha hecho seguir otra serie de principios de desarrollo como:
- YAGNI: You Ain’t Gonna Need It. TDD nos ayuda a prevenir la escritura de código que no va a ser utilizado en nuestra aplicación. Básicamente porque solo escribimos lo mínimo necesario para cubrir las especificaciones.
- Menos uso del debugger: se dice que los buenos programadores de TDD dejan de usar el debugger, ya que no lo necesitan. Todo su código ya está probado. ;P
- Interface Segregation Principle: es un principio SOLID (la ‘i’ concretamente) que dice que debemos segregar las responsabilidades en interfaces. TDD nos obliga a separar componente según responsabilidad porque los test unitarios como norma, no pueden comprobar más de una funcionalidad en un solo artefacto (unitario).
- Dependency Injection: el patrón de inyección de dependencias dice que deberíamos crear un contendor que sea quien controle y resuelva las dependencias de todos los artefactos de nuestra aplicación. Y seguiremos este patrón para facilitarnos la creación de objetos mediante interfaces correctamente segregadas.
- Y estos dos últimos punto nos llevan a seguir otro principio de SOLID: Dependency Inversion Principle. Que dice que una clase debería de depender de las abstracciones y no al contrario.
- Desarrollaremos siguiendo los principios ágiles: dividimos el problema en pequeños pasos y lo vamos solucionando uno a uno. Buscaremos especificaciones y las codificaremos una a una con su test unitario. Nos adaptaremos a los cambios rápidamente.
- Y algo más evidente como que tendremos una mayor cobertura de código con test unitarios. Esto nos aportará una red de seguridad de cara a los cambios, ya que si alguien cambia algo que hace fallar una especificación, por antigua que esta sea, un test fallará.
Y hasta aquí puedo escribir, debajo encontrareis el archivo con la presentación de la ponencia…