Hoy he venido contaros mis experiencias ayudando a diferentes empresas en la subida de sus aplicaciones a azure, y concretamente a azure PaaS. Así que en realidad no son mis experiencias, son las de esas empresas. Y si soy totalmente sincero, no son sus experiencias, en realidad de lo que os voy a hablar es de sus quejas.
Un poco de historia
Dejad que os cuente una pequeña historia:
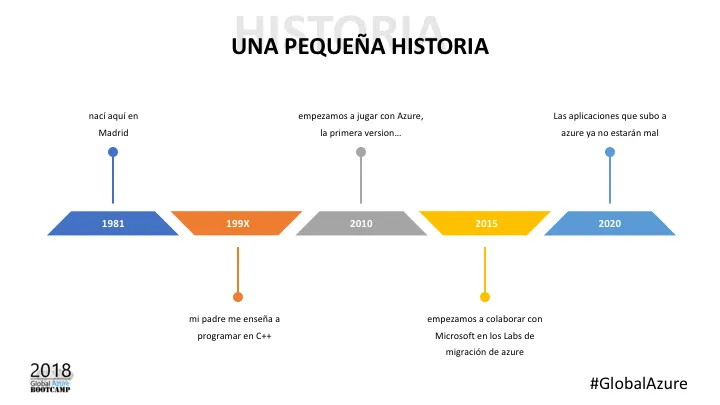
Todo empezó en 1981, cuando nací. Aquí en Madrid. Desde entonces he estado muy cerca de los ordenadores. La década de los 90 mi padre me estuvo enseñando C++. Ahí estaba yo con Visual Studio y las Microsoft Foundation Classes. Sin entender muy bien exactamente por qué se dibujaba un botón en la pantalla.
El caso es que aunque mi vida es muy divertida, en realidad lo que hoy nos interesa es la experiencia que puedo aportar en azure. Esto empezó en 2010, cuando aún lo llamábamos Windows Azure. El portal de gestión estaba hecho en una tecnología llamada a “petarlo” en programación web como es… era Silverlight. Ahí conocimos los storages y cloud services. Nos peleamos con el auto escalado usando Wasabi y en relidad todo era mucho más difícil que ahora.
Por ahí por el 2015 Microsoft nos propuso a Tokiota colaborar con ellos en unas jornadas que servían para ayudar a otras empresas a subir a sus aplicaciones a azure. Y ahí es cuando realmente empezamos a pelearnos y a aprender con retos de todo tipo, que hoy veremos.
El camino a la nube
Supongo que todos los aquí presentes habrán hecho alguno de los tutoriales de la extensa y a la vez excelsa documentación que Microsoft tiene a nuestra disposición en internet. Todo funciona genial. Creo que la primera vez que escuche eso de “azure nos obliga a programar bien” fue a Gisela Torres. En una charla no muy diferente de esta. Y es verdad. Esto está genial. Pero no cuando ya tienes una aplicación desarrollada que no ha sido pensada para ser subida a la nube, la cosa cambia.

Así que decidimos hacer un “ABC”. Una especie de metodología, guía o industrialización de las migraciones que estábamos realizando. Y lo llamamos “el camino a la nube”. Lo simplificamos de tal manera que lo resumimos en 4 sencillos pasos.
Básicamente se trataba de conseguir que las aplicaciones de estas empresas fueran escalables horizontalmente. Así que nos fijamos solo en los recursos:
-
Los archivos que se generan o que se suben a esta aplicación ya no pueden estar en el propio “file system” del servidor que la contiene. Al poder tener muchas instancias hay que almacenarlos en una unidad compartida. Por ejemplo, un blob storage.
-
Las variables de sesión. Sí ya sé que aquí todos programamos servicios stateless. Pero esto no ha sido así siempre. A lo que iba: Las variables de sesión deberían estar en un almacén compartido y que sea rápido. Como por ejemplo un redis cache.
-
Y esto nos lleva al uso de una caché. Si nuestra aplicación, con el fin de tener los datos de una forma más dinámica, usa una memoria caché, esta tiene que ser provista por un servicio externo y compartido. Como por ejemplo el ya mencionado azure redis cache.
-
Para terminar, nos teníamos que fijar en la base de datos. Hay ciertas incompatibilidades con respecto un sql server completo a uno en la nube. Y afortunadamente disponemos de varias herramientas que nos pueden ayudar con esta tares.
Si teníamos resueltos estos casos ya estábamos listos para poder subir a la nube… ¿o no?
Empiezan los problemas
Nuestro camino a la nube se había visto muy eficaz en la migración de muchas clases de WebApps, pero fue justo entonces cuando comenzaron los problemas. Las compañías a las que ayudábamos estaban poniendo sus aplicaciones en producción en la nube, estaban empezando a investigar por su cuenta y a tomarse licencias fuera de lo que nosotros considerábamos como una mera prueba de concepto. Un pequeño empujón que les ayudaría a usar los servicios PaaS de azure.

Nuestros desarrollos internos funcionaban genial. Es más, en Tokiota no tenemos servidores, usamos azure. Y estábamos muy contentos con la calidad del servicio.
Pero para las empresas que ayudábamos, la cosa no estaba yendo bien. ¿Quizá nos habíamos confundido? ¿quizá azure no era tan bueno? ¿es posible que tuviéramos que revisar todo nuestro proceso y prestar más atención a los detalles?
Posiblemente sí. Y es aquí donde surge el enfado. El enfado lleva al odio. Y al final desemboca en una fase de apatía. (no en el lado oscuro ;P)
Para evitar este devenir de los sentimientos teníamos un plan. Apuntamos lo que nos decían esas empresas y debajo añadíamos nuestras notas sobre la solución. Al documento resultando lo llamamos “Mis Notas”. Así todos los consultores lo considerarían suyo. Podrían modificarlo. Añadir o borrar nueva información.
Y lo que hoy os traigo son lagunas de las notas más destacadas de “Mis Notas”:
EN MI MÁQUINA VA GENIAL, PERO CUANDO SUBO LO MISMO A AZURE VA SUPER LENTO
Esta frase es la sustitución del mítico “Works in my machine” o “En mi máquina funciona”. Y jamás he puesto en duda semejante afirmación. Pero claro, si mi portátil es un i7 con 16 Gb de RAM y 512 Gb de SSD y en azure me decanto por una máquina con 1 core y 1,75Gb de RAM y HDD virtual… Y eso sin contar con el tema de que en mi máquina estoy lanzando un servidor de desarrollo al que solo accedo yo (como podría ser IIS Express), mientras que en azure están entrando tropecientos usuarios a la vez.

Aunque en realidad nosotros en nuestras aplicaciones con 100 usuario concurrentes y una instancia de las más pequeñas no hemos encontrado problemas…
De cualquier forma, uno de los puntos que siempre hay que revisar en azure es que todos los servicios de usemos en una aplicación estén hospedados en la misma región. En el mismo data center. Primero por los temas de performance, pero segundo porque además el tráfico de azure a azure en el mismo datacenter no nos lo cobran.
Otro detalle que es importante es usar al menos instancias estándar o “S” en nuestros servicios de producción. Y a partir de estos tamaños buscar el más adecuado para hospedar nuestro servicio. A parte de los típicos valores de CPU, RAM y disco, también vienen asociadas con el tamaño de una instancia otros factores como el número de conexiones, las I/Os… que son muy importantes también.
Y el último consejo en general para usar cualquier servicio de azure es realizar siempre procesos cortos. Si por A o por B tenemos un proceso que nos va a llevar mucho tiempo (y cuando digo mucho es más de 1 segundo) lo mejor que podemos hacer es distribuirlo y ejecutarlo en los servicios adecuados para estas tareas como por ejemplo WebJobs, Azure Functions o si tenemos algo grande de verdad un azure batch.
Si AAD ya tiene gestor de usuarios, ¿para qué hacer el mío dentro de mi aplicación?
No cometáis este grabe error. Os perseguirá el resto de vuestra vida laboral.

Lo primero que tenemos que hacer es conocer que es lo que hace AAD cuando delegamos la autenticación y autorización de usuarios. Autenticación es ese proceso en el que validamos que un usuario es en realidad quien dice ser. Autorización es cuando decidimos si un usuario tiene permisos para ver un recurso en concreto (nuestra webapp).
Si dejamos que nuestro gestor de usuarios sea el AAD: qué pasa si borramos un usuario? Perderíamos todos sus datos? como no podemos hacer login con ese usuario queda en un estado de limbo dentro de nuestra aplicación o como va eso?
Siempre recomendaré que la autenticación la realice AAD por nosotros. E incluso el tema de autorización para entrar en nuestra página web. Pero el tema de la autorización sobre datos concretos de nuestra aplicación tenemos que gestionarla nosotros.
Así que os recomiendo:
-
Almacenar los usuarios de AAD en nuestra aplicación. Incluso podríamos decidir crear un usuario si no existe en el login.
-
Este usuario relacionarlo con el usuario del AAD vía el UPN. Pero que tenga su propio ID.
-
Almacenar los permisos dentro de la aplicación (si es que son necesarios) en nuestra aplicación y relacionados con el usuario de nuestra aplicación.
-
Si necesitamos relacionar algún dato con un usuario no usar el UPN más que para el propio usuario. En el resto de datos relacionarlo con los usuarios internos de la aplicación.
EL SERVICIO DE AZURE REDIS CACHE ES MUY LENTO…
Redis es de las bases de datos relacionales más rápidas que existen. Trabaja en memoria lo que la hace ideal para comportarse como un servicio de caché. Así que, si redis funciona lento, lo más razonable es que el problema no sea de redis.

-
Lo primero que debes hacer es activar desde el portal el “Redis cache advisor”, un asistente/herramienta que detectará y avisará sobre los defectos típicos que podamos tener a la hora de gestionar redis.
-
Por mi experiencia los problemas suelen estar en almacenar valores muy grandes dentro de una sola key. Algo muy común cuando heredamos una aplicación que se programó usando variables de sesión en memoria local. Aunque redis soporta sin problemas valores bastante grandes, si queremos sacarle partido a sus características lo mejor es almacenar muchas keys con valores más pequeños. Si necesitamos recoger y pre filtrar varias de esas opciones en una sola consulta; redis nos puede ayudar dándonos muestras de lo realmente rápido que es.
-
Igual que nos sucede con los demás servicios de azure, pero en redis lo miramos menos porque es un poco más caro: hay que conocer los detalles de límites de conexiones concurrentes en cada tamaño de instancia de redis. Puede ser que los problemas que experimentamos de rendimiento se deban a que tenemos muchas más conexiones de las que somos capaces de gestionar y esto hace que se vayan creando nuevas conexiones cada poco. Lo cual enlentece mucho la experiencia.
-
Como nota, aunque nada recomendable, os puedo decir que el cifrado SSL le sienta especialmente mal al protocolo que usa redis para comunicarse. Así que, si tenéis redis en dentro de una vnet y sin acceso desde otro lugar que no sea esa vnet, podéis desactivar el SSL y ver cómo se incrementa la velocidad.
-
Y por último, sobre todo para aquellos que trabajáis con lenguajes como PHP o nodejs, existe un gateway simulado dentro de los appservices para poder usar redis usando el protocolo de memcached. Y es realmente eficiente si solo queremos usarlo como caché. Aunque así nos perderíamos las otras grandes ventajas que tiene redis…
ESTOY MUY CONTENTO CON EL SERVICIO DE COSMOS DB PERO ES CARÍSIMO
¿Qué entendemos como caro?

Esta frase es muy frecuente y es porque dentro de Cosmos DB, una colección es tratada, por así decirlo, como una base de datos. Las colecciones se facturan por separado y la colección mínima que podemos contratar es de 400 RU. Teniendo en cuenta que el precio por RU es más o menos 5 € por cada 100, el precio mínimo de una colección es de unos 20 €.
Si a esto le sumamos que cada “entidad” (como si fueran tablas de entity framework) la guardamos en una colección diferente y tenemos, por decir algo, 18 entidades: serían unos 300 € al mes con el añadido de que estamos (infra) usando 7200 RUs.
Si lo vemos así no es tan caro. Así que os proponemos 3 ideas:
-
La primera es que una colección de cosmos DB almacena documentos sin esquema. Eso se traduce en que podemos tener documentos con diferentes propiedades (y por tanto diferentes tipos de documento) en una sola colección.
-
La segunda es que las colecciones se pueden particionar por algún valor de alguna propiedad. Si por ejemplo creamos en todas nuestras entidades una propiedad que sea el tipo de entidad como un string podríamos particionar físicamente los datos para que fuera más eficiente acceder a ellos.
-
Y la tercera es que no penséis en tablas cuando uséis cosmos DB, pensad en documentos. Y si no usad mejor sql database.
Como bola extra os comentaré que cuando usamos el cliente de .net lo mejor es usar las llamadas asíncronas y la conexión hacerla por TCP y activando el “direct mode”.
SE ME BLOQUEA LA BASE DE DATOS EN LOS MOMENTOS DE MAYOR USO Y YA NO PUEDO ESCALAR MÁS
Con el servicio de SQL database nos hemos encontrado un festival de problemas de “performance”. Aunque generalmente se debe a que la gente está acostumbrada al cluster de su empresa de SQL Server que tiene 3 servidores con 64Gb de RAM, las cabinas de la leche que se conectan con fibra y bueno, la factura que da miedo.

Estos servidores suelen ocultar las operaciones que tienen una performance fatal. Así que cuando vamos al servicio PaaS de azure de base de datos, como usamos instancias pequeñas, se hacen evidentes. Pero no os estoy diciendo que uséis tamaños más grandes de SQL Database. Creo que sale más rentable invertir en mejorar nuestra queries.
-
La primera recomendación cuando usamos SQL Database es que migremos usando los asistentes de SSMS.
-
Lo segundo que debemos hacer es activar el SQL Database Advisor, que al igual que el de redis, nos va a avisar de aquellos defectos típicos que encuentre. E incluso nos propondrá realizar modificaciones en el esquema de la base de datos. Como por ejemplo, proponiéndonos índices nuevos.
-
Supongo que no soy el primero en decirlo, pero no almacenéis la lógica de negocio embebida en la base de datos en forma de stored procedures con transacciones. Si estos procesos son muy largos, al final lo que vais a conseguir es bloquear muchas tablas y como consecuencia a todos los demás usuarios que acceden a la web.
-
Usad la herramienta que nos proporciona el portal de azure “query performance insight” para poder medir la eficiencia de vuestras queries.
-
Para saber el tamaño de instancia que necesitamos en azure, como se usa el término DTU para ello, tenemos un DTU calculator online que nos puede ayudar.
¡CLARO! COMO AZURE ES DE MICROSOFT LAS APLICACIONES DESARROLLADAS EN NODE VAN FATAL
Ahora empezamos con la ronda de mentiras. Nodejs funciona en los application services genial. Pero si que es verdad que tenemos que tener en cuenta que si usamos instancias con windows, nodejs se usa mediante el módulo de IIS llamado IISNODE. Y este módulo tiene ciertas peculiaridades:

-
Los node cluster (haciendo master y slave) no funcionan a través del IISNODE. A cambio hay unos parámetros de configuración que se le pueden pasar en el web.config o en un fichero a parte llamado “iisnode.yml” donde además de muchas otras cosas podremos configurar cuantas instancias de node queremos que lance el IISNODE.
-
Si vamos a usar sockets tenemos que activarlo en la configuración del portal. Si no simplemente se bloquean.
-
Si no tenemos buena performance, podemos probar a usar el paquete de npm llamado v8-profiler, que se integra con chrome y bueno, nos puede resolver muchas dudas sobre donde estamos teniendo problemas.
MICROSOFT HACE QUE LAS APLICACIONES DE PHP SE ARRASTREN PARA QUE PROGRAMES EN .NET
Si me conocéis sabréis que soy programador fundamentalmente de .net, no de PHP ni Java. Así que en estos puntos no os podré dar tantos consejos. Pero si que tengo algunos sobre las aplicaciones en PHP como por ejemplo wordpress:

-
El app services (windows) el archivo “php.ini” se sustituye por el “.user.ini”. Jugad ahí con las diferentes configuraciones generales de PHP.
-
Podemos añadir extensiones a PHP en forma de binarios subiéndolos a una carpeta junto con nuestra aplicación e indicando que las cargue bien por un parámetro de configuración del servicio o bien en el archivo .ini. Así que ya no hay escusas para no usar memcached ;).
-
Usad siempre la versión más alta de PHP. Sobre todo a partir de la 7, donde mejora muchísimo la performace en comparación con por ejemplo la 4.X.
-
Y por último, hay pequeños trucos mezclando memcached, con IIS y con las cachés, que mediante configuraciones que podréis encontrar en internet nos ayudarán a que haya páginas de php que sean guardadas en la caché y que la velocidad de nuestra aplicación se incremente muchísimo.
¿FUNCIONA TOMCAT EN AZURE? BUENO, YO TENGO MI PROPIO TOMCAT CUSTOMIZADO…
Aun recuerdo la primera vez que una empresa vino con su Tomcat customizado. Y las que les han seguido!. Tomcat funciona en App Services. Y puedes subir el tuyo customizado. Lo más recomendable es buscar en la galería una Web App con la última versión de Tomcat. Este template se descarga el tomcat desde los servidores oficiales a la WebApp. Una vez ahí, solo tienes que sustituirlo por el tuyo. Aunque es muy posible que le tengas que hacer retoques. No es lo mismo un tomcat en tu datacenter que en azure…
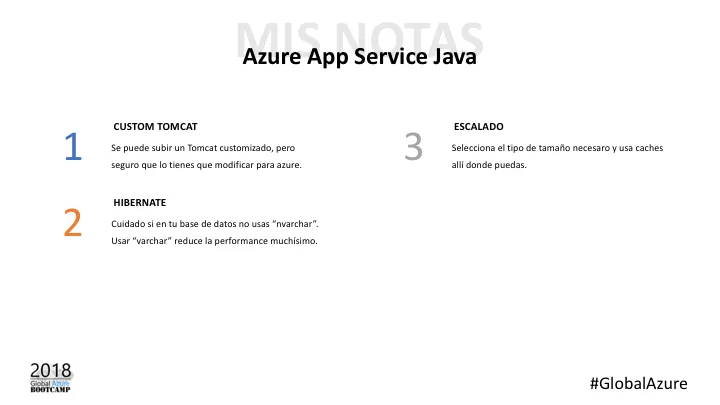
A parte de las típicas recomendaciones de cuidado con el tamaño de la instancia y el usa cachés allí donde puedas, nos encontramos también una pequeña curiosidad:
- Usando Hibernate, el conocido ORM de java, tienes que garantizar que todas las cadenas de tu base de datos sean “nvarchar” y no “varchar” a secas. Resulta que Hibernate trabaja con caracteres unicode sí o sí, así que si no usas nvarchar los convierte. Esto hace que la performance caiga en picado.
ES QUE AZURE ES MUY CARO
Y hemos llegado a la penúltima frase que más hemos oído migrando aplicaciones a azure: es muy caro.

-
Azure no es válido para todo el mundo. Si una empresa tiene un pequeño aplicativo en un hosting de 100€ al año que es muy lento y no tiene SLAs, azure le va a resultar muy caro. Posiblemente la plataforma no sea para ellos.
-
Pero si tenemos en cuenta que 24x7, los SLAs de 99,9[5 9] de disponibilidad, que por ejemplo 1Tb con sus 3 replicas solo cuestan 16 € al mes… Creo que ya lo hemos dicho todo…
SI no me lo arregla Microsoft, ME VOY A IR A AMAZON
Y por último el ganador. La persona que como no está contenta con su aplicación te suelta una amenaza. A mi ni me va ni me viene. Yo no trabajo en Microsoft. Pero la gente te lo dice igualmente.

Mi respuesta se divide en dos puntos:
-
AWS es una gran plataforma cloud. En algunos aspectos es muy posible que sea superior a Azure. Y en otros será Azure quien es superior. En el tema de PaaS a mi personalmente me gusta mucho azure y la forma de exponer sus precios. Pero es válido tener AWS e incluso más de un proveedor de cloud. La diversificación es buena para una empresa. No atarse…
-
Y por último: si en Azure te funciona mal… en amazon por el mismo precio, no lo va a hacer mejor.
En resumen
Así que intentando responder a la pregunta retórica que formulábamos al inicio de la sesión: ¿Por qué todo lo que subo a azure está mal?
Pues posiblemente porque está mal. Y encima la culpa es mía.